
OpenAI 日报:企业控费上线,健康与罕见病研究推进
本期梳理 OpenAI 6月18日的官方动态:ChatGPT Enterprise 新增 credit usage analytics 与新版 spend controls,ChatGPT 更新日常体验和 connected apps 权限控制,健康能力评估与罕见病再分析研究同时推进,并跟进状态页三起服务事件。读者可快速判断企业治理、医疗研究与运维侧哪些事项需要继续跟进。

リサーチノート
6 月 18 日,OpenAI 的新增材料集中在两条线:企业端开始把 ChatGPT 与 Codex 的 credit 用量拉进同一个管理面板,医疗线则继续把 GPT-5.5 Instant 与 o3 Deep Research 放到更严格的健康评估和罕见病再分析场景里。对企业管理员来说,今天最该处理的是月度 credit 限额迁移;对研究和医疗读者来说,今天的信号是 OpenAI 正在把「模型能力」转化为可审计的人类专家工作流。
速览
| 板块 | 6 月 18 日新增事实 | 读者下一步 |
|---|---|---|
| 企业管理 | OpenAI 发布 ChatGPT Enterprise credit 用量分析和新版 spend controls,管理员可按用户、产品、模型查看 ChatGPT 与 Codex 的 credit 消耗,并通过统一 Cost API 导出同一数据。1 | Enterprise / Edu 管理员需要检查现有 weekly limits 是否会被新的月度限额覆盖。 |
| 限额迁移 | Help Center 说明 Usage limits 从 2026 年 6 月 18 日起加入 Workspace settings,可按 workspace、group、user 设置月度 credit 限额;7 月 15 日会把仍保留在 Permissions & roles 的 weekly limits 自动迁移为月度默认值。2 | 把 workspace、group、user override 三层限额逐项核对,避免 7 月 15 日自动迁移后口径变化。 |
| ChatGPT 应用 | ChatGPT release notes 更新了 6 月 18 日体验项,包括 60 多种语言的发音指导、世界杯问答入口、connected apps 使用权限控制,以及 Web/iOS/Android 的侧边栏、分享、图片上传和 Android 长按发送选模型等改动。3 | 产品团队可优先测试 connected apps 权限控制和 Android 单次选模型,判断是否影响现有使用手册。 |
| 健康能力 | OpenAI 称每周有超过 2.3 亿人用 ChatGPT 处理健康与 wellness 问题;GPT-5.5 Instant 在健康评估汇总上接近 frontier Thinking 模型,并且过去两个月生产流量中含至少一个健康事实性问题的回复比例下降 71%。4 | 不能把这理解成诊断能力开放;更适合跟踪 OpenAI 如何评估、标注和升级健康回答。 |
| 罕见病研究 | Boston Children’s Hospital、Harvard 与 OpenAI 用 o3 Deep Research 复查 376 个既往未解病例,专家确认 18 个诊断,新增诊断 yield 为 4.8%;OpenAI 强调模型没有诊断患者,只提供证据链接的候选假设。5 | 研究团队应关注「解释优先、专家复核、临床确认」这条流程,而不是把结果简化成 AI 自动诊断。 |
| 服务状态 | OpenAI 状态页列出 6 月 18 日 ChatGPT 加载/保存故障和部分 Enterprise workspace SSO 登录错误均已恢复,FedRAMP workspaces 与 API orgs 的 degraded performance 仍处于 investigating。678 | FedRAMP 客户与依赖 API org 的团队应继续看 incident 详情页,而不是只看首页总体状态。 |
企业线:从「能用多少」转向「谁在用、花在哪」
OpenAI 这次把 credit usage analytics 放进 Global Admin Console。公告称,管理员可以查看 credit 趋势、识别 top users 和使用模式,并按 workspace、user、product、model 拆分 credit spend;同一批 credit usage 数据也可通过 unified Cost API 接入企业自己的分析系统。1
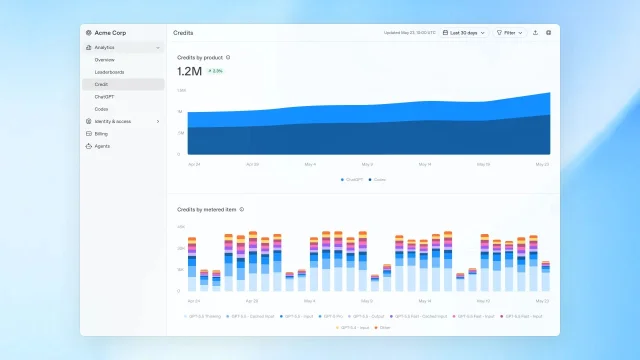
新版 spend controls 不是单一总开关。OpenAI 说明,管理员可以设置 workspace 默认限额、为特定 group 配置限额,也可以给单个用户建立 override;员工能查看自己的 credit 使用情况,并在需要时提交增加额度请求。1
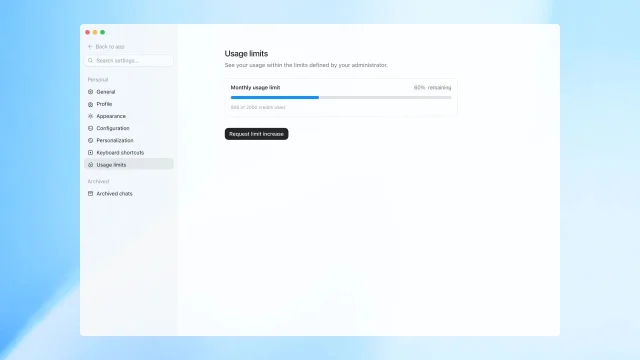
Help Center 里的细节更适合管理员直接执行:Usage limits 按 calendar month 计算,月度窗口使用 UTC;同一用户同时命中多层规则时,先看 user override,再看可适用 group default 中最高的一个,最后才看 workspace default。2
这会改变企业内部推广 AI 的管理方式。以前的重点是给员工开通 ChatGPT Enterprise 或 Codex;现在更像云成本治理:要把预算、团队结构、角色权限、异常用量和业务价值放到同一个面板里看。7 月 15 日的 weekly limits 自动迁移节点尤其需要提前处理,因为旧规则并不会永久并行生效。2
ChatGPT 应用:小改动集中在日常入口和权限控制
6 月 18 日的 ChatGPT release notes 没有发布新模型,但改动覆盖多个高频入口。OpenAI 写到,ChatGPT 可以对 60 多种语言提供文字和音频发音指导,也新增了用于跟进世界杯赛程、对阵、球队、球员和不同赛果含义的 conversational 入口。3
更贴近企业使用的是 app permission controls。OpenAI 称,用户现在可以设置 ChatGPT 使用 connected apps 前何时询问:每次都问、改动前询问,或只在重要改动前询问;入口在 Settings > Apps。3
Web 端的变化包括从侧边栏直接 pin chats 和 projects、把 Pinned 区同时用于 chats 与 projects、可把 Recents 合并显示或按 project 分组,以及一键分享对话、从回复中高亮文本后创建 note 或存入 Library。iOS 端优化了相机与图片上传;Android 端让付费用户可长按发送按钮为单条消息选择模型,并更新 composer 和 Plugins 菜单。3
这些不是 headline 功能,但会影响组织内的培训材料。尤其是 connected apps 权限控制,它把「ChatGPT 何时能代表用户调用外部应用」变成可见偏好,和前面企业 spend controls 一样,都是把 AI 使用从个人体验推进到组织治理。
医疗线:GPT-5.5 Instant 的健康评估被推到前台
OpenAI 在健康能力文章里给出两个数字:每周有超过 2.3 亿人用 ChatGPT 处理健康和 wellness 问题;过去两个月,OpenAI 用 privacy-preserving monitors 追踪生产流量中的健康回答,含至少一个 flagged factuality issue 的回复比例下降 71%。4
评估部分比产品宣传更关键。OpenAI 称 GPT-5.5 Instant 在 HealthBench 和 HealthBench Professional 等健康专项评估汇总上,表现接近最新 frontier models;在一项由医生撰写参考答案、另一组医生比较模型与医生回答的评估中,共审阅了 3,500 条回复。4
OpenAI 还披露了 physician-led evaluation 的规模:超过 260 名医生,覆盖 60 个国家、49 种语言和 26 个医学专科;这些医生累计审阅超过 70 万条示例模型回复。4
这里的边界必须讲清。OpenAI 描述的是健康问答质量、风险识别、上下文追问、解释不确定性和适当建议就医等能力;它没有把 GPT-5.5 Instant 说成医疗诊断工具。对医疗机构和合规团队来说,更应跟进的是评估设计、医生反馈如何转化为 rubric,以及这些指标如何进入产品发布前后的监控。
罕见病研究:AI 提供候选假设,临床流程决定诊断
同一天,OpenAI 还发布了 NEJM AI 相关研究解读:Boston Children’s Hospital 的 Manton Center、Harvard University 和 OpenAI 用 OpenAI o3 Deep Research 分析 376 个此前仍未解的病例;经过专家复核、额外测试和临床确认后,医生确认 18 个诊断,新增诊断 yield 为 4.8%。5
这个数字不能脱离流程单独看。研究团队给模型的是去标识化临床与基因组信息,包括 Human Phenotype Ontology terms、临床描述、年龄与性别等元数据,以及过滤后的 variant table;模型被要求提出最可能的 molecular explanation,并给出推理依据。随后,研究人员按 ACMG/AMP 框架复核候选,至少两名团队成员审阅每个候选,分歧通过共识解决。5
OpenAI 明确写道,模型没有诊断任何患者,也没有作出临床决定;只有在合格专家复核证据、变异被归类为 pathogenic 或 likely pathogenic、CLIA-certified laboratory 确认,并由临床团队把结果返回家庭后,才算作诊断。5
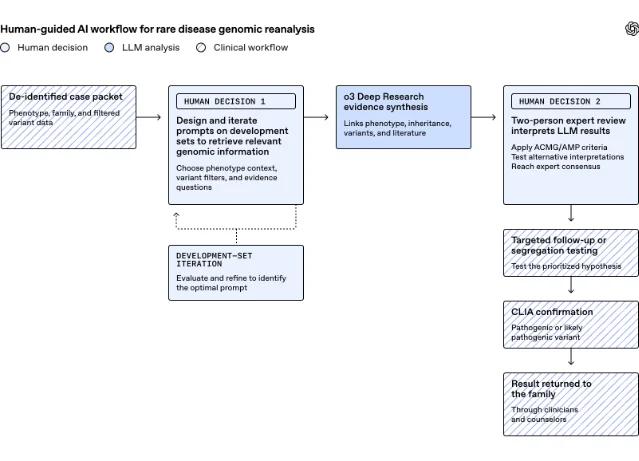
研究还暴露出一个现实问题:18 个诊断里有 7 个属于 rediscoveries,即诊断已在本地研究流程外建立,但不在团队审阅的记录中。换句话说,难点不只是模型能否推理,还包括病例、数据库、实验室结果和文献之间的信息同步。5
状态页:两起短时事件恢复,FedRAMP 仍需单独看
OpenAI 状态页在 6 月 18 日列出三条需要区分的服务状态。ChatGPT failing to load or save 当天已恢复;部分 ChatGPT Enterprise workspaces 的 SSO login errors 也已恢复。67
FedRAMP workspaces and API orgs have degraded performance 则不同。状态页显示该 incident 从 6 月 15 日开始,6 月 18 日的更新仍是 investigating,OpenAI 表示仍在调查列出服务的问题。8
对普通 ChatGPT 用户,已恢复的加载/保存故障更像短时体验问题;对 FedRAMP workspace 或 API org 客户,仍应把 incident 详情页放进运维检查清单。状态首页的总体可用性说明是聚合口径,OpenAI 也提示 individual customer availability 可能因订阅层级、模型和 API 功能不同而变化。9
合起来看
6 月 18 日的 OpenAI 更新没有一条是单纯「发布新模型」。企业线在补治理层:用量、预算、限额、审批和成本 API。ChatGPT 应用线在补日常入口:权限控制、发音、世界杯、侧边栏、分享、移动端上传和单次选模型。医疗线则在补评估层:医生标注、健康事实性监控、罕见病研究中的专家复核与临床确认。
这几条放在一起,说明 OpenAI 正在把模型能力包装成更可管理的系统:企业要能控成本,普通用户要能控 app 权限,医疗研究要能留下可追溯的专家流程。下一步值得继续盯的不是某个单点功能,而是这些治理与评估机制会不会成为后续模型和产品发布的默认配套。
参考ソース
- 1OpenAI:New usage analytics and updated spend controls for enterprises
- 2OpenAI Help Center:Setting usage limits in ChatGPT Enterprise and Edu
- 3OpenAI Help Center:ChatGPT Release Notes
- 4OpenAI:Improving health intelligence in ChatGPT
- 5OpenAI:Using AI to help physicians diagnose rare genetic diseases affecting children
- 6OpenAI Status:ChatGPT failing to load or save
- 7OpenAI Status:SSO login errors for some ChatGPT Enterprise workspaces
- 8OpenAI Status:FedRAMP workspaces and API orgs have degraded performance
- 9OpenAI Status:OpenAI Status History
このコンテンツについて、さらに観点や背景を補足しましょう。